
Open-vocabulary querying in 3D space is challenging but essential for scene understanding tasks such as object localization and segmentation. Language-embedded scene representations have made progress by incorporating language features into 3D spaces. However, their efficacy heavily depends on neural networks that are resource-intensive in training and rendering. Although recent 3D Gaussians offer efficient and high-quality novel view synthesis, directly embedding language features in them leads to prohibitive memory usage and decreased performance. In this work, we introduce Language Embedded 3D Gaussians, a novel scene representation for open-vocabulary query tasks. Instead of embedding high-dimensional raw semantic features on 3D Gaussians, we propose a dedicated quantization scheme that drastically alleviates the memory requirement, and a novel embedding procedure that achieves smoother yet high accuracy query, countering the multi-view feature inconsistencies and the high-frequency inductive bias in point-based representations. Our comprehensive experiments show that our representation achieves the best visual quality and language querying accuracy across current language-embedded representations, while maintaining real-time rendering frame rates on a single desktop GPU.
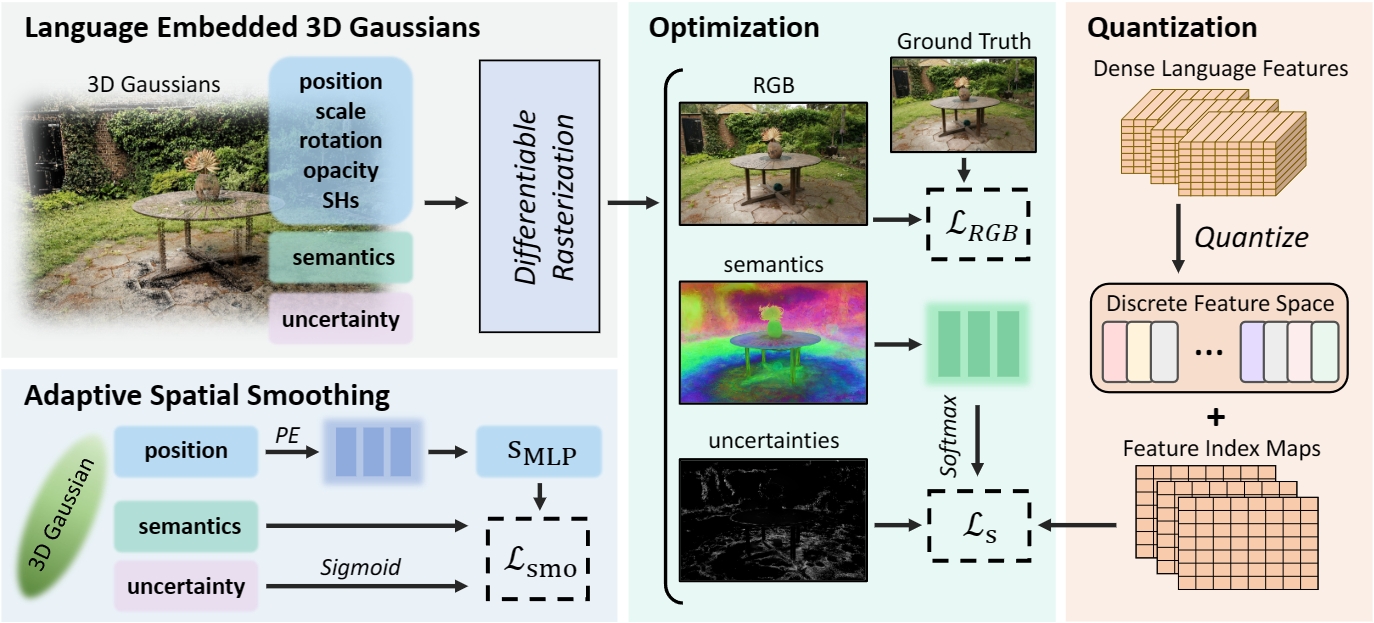
The training process for Language-embedded 3D Gaussians starts with initializing scenes following 3D Gaussian Splatting and randomly initializing semantic features and setting uncertainty to zero. Dense language features from multi-view CLIP and DINO are quantized to create a discrete feature space and semantic indices. These attributes of the 3D Gaussians are then rendered into 2D maps using a differentiable rasterizer. The optimization is achieved through semantic and adaptive spatial smoothing loss.
Quantitative comparison of our method with DFF, LeRF, 3DOVS.
The table presents a comparison across various metrics, including novel view synthesis quality, open-vocabulary query accuracy, and computational efficiency. We report both host memory and video memory usage, as well as the disk space used for storing the learned language features. Our approach outperforms others in rendering quality and semantic query accuracy, while also offering lower computational demands and a significant speed increase, nearly 100 times faster in inference.

Comparison of novel view synthesis and query relevance visualization. Left to right: Ground truth novel view synthesis, novel view images with relevance visualization from our method, DFF, LeRF, and 3DOVS. Top to bottom: Query words ``asphalt ground'', ``bicycle'', ``jar of coconut oil'', ``flower'', ``LEGO Technic 856 Bulldozer'', and ``brown shoes''.

Examples of various open-vocabulary queries.
Our approach enables accurate open-vocabulary queries using a diverse class of word types, including but not limited to, visual attributes, general terms, materials, olfactory properties, and related actions.

If you find this work useful for your research, please cite:
@inproceedings{shi2024language,
title={Language embedded 3d gaussians for open-vocabulary scene understanding},
author={Shi, Jin-Chuan and Wang, Miao and Duan, Hao-Bin and Guan, Shao-Hua},
booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition},
pages={5333--5343},
year={2024}
}@article{wang2025language,
title={Language Embedded 3D Gaussians for Open-Vocabulary Scene Querying},
author={Wang, Miao and Shi, Jin-Chuan and Guan, Shao-Hua and Duan, Hao-Bin},
journal={IEEE Transactions on Pattern Analysis and Machine Intelligence},
year={2025},
publisher={IEEE}
}